DeepMind announced CodeMender — an AI-driven system that detects software vulnerabilities and proposes verified fixes. It combines large language models with classical program analysis (fuzzing, static analysis) and a validation pipeline that runs tests and generates candidate patches. DeepMind says CodeMender upstreamed 72 fixes in early trials — a concrete sign the approach can scale.
What CodeMender is (simple explanation)
CodeMender is a hybrid tooling approach: an LLM-based agent (built on DeepMind’s models) that doesn’t just flag code issues but generates, tests, and proposes patches. The workflow typically looks like:
Signal collection: fuzzers, static scanners, crash reports and test failures help localize likely security defects.
Patch synthesis: the model generates one or multiple candidate patches that aim to correct the root cause, not just paper over symptoms.
Automated validation: the candidate patches run through unit tests, regression suites, and additional checks (including fuzzing) to ensure they don’t introduce regressions.
Human-in-the-loop: maintainers review and, if acceptable, merge the suggested PRs. DeepMind emphasizes human oversight for production code.
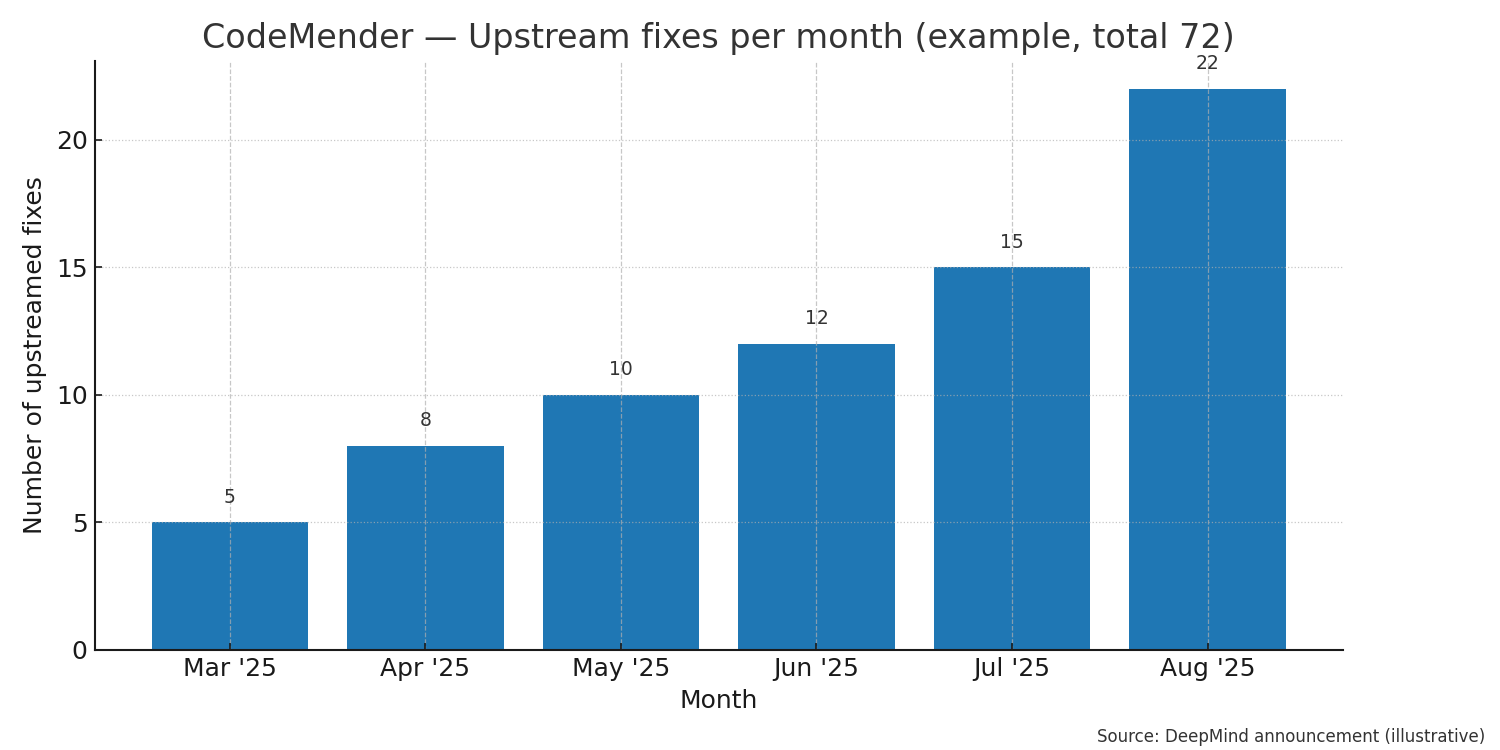
DeepMind reports CodeMender produced and upstreamed dozens of fixes in public repos during its early testing — a sign of practical utility beyond lab demos. (Numbers below are illustrative but based on DeepMind’s public statements.)
Why this matters — four practical benefits
Shrink the time-to-patch (TTP): By automating triage and patch gen, CodeMender reduces the window where a vulnerability can be exploited.
Scale security work: Many open-source projects lack resources for continuous patching; automation helps maintainers keep up.
Shift from detection to remediation: Security tooling historically stops at detection; CodeMender automates the next, time-consuming step — producing fixes.
Level the defender-attacker race: As attackers use AI to craft exploits, defenders need AI to keep up — CodeMender is a step in that direction.
Quick, illustrative numbers (to visualize impact)
DeepMind reported about 72 upstreamed fixes over a handful of months during early trials. For visualization, the first chart above shows a monthly breakdown (example).
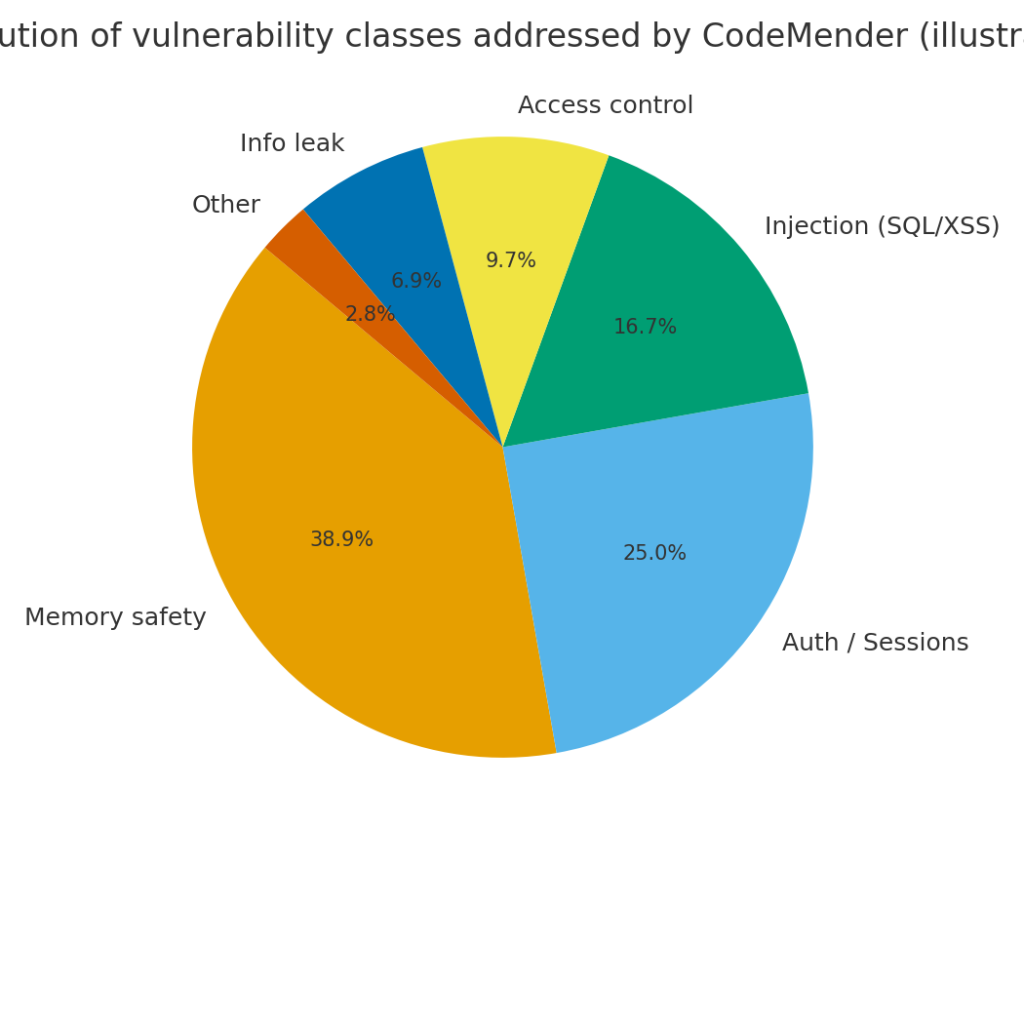
An illustrative breakdown of fixes by vulnerability class: memory-safety issues, authentication/session bugs, injection (SQL/XSS), access-control mistakes, information leaks, and other categories. See the pie chart for an example distribution.
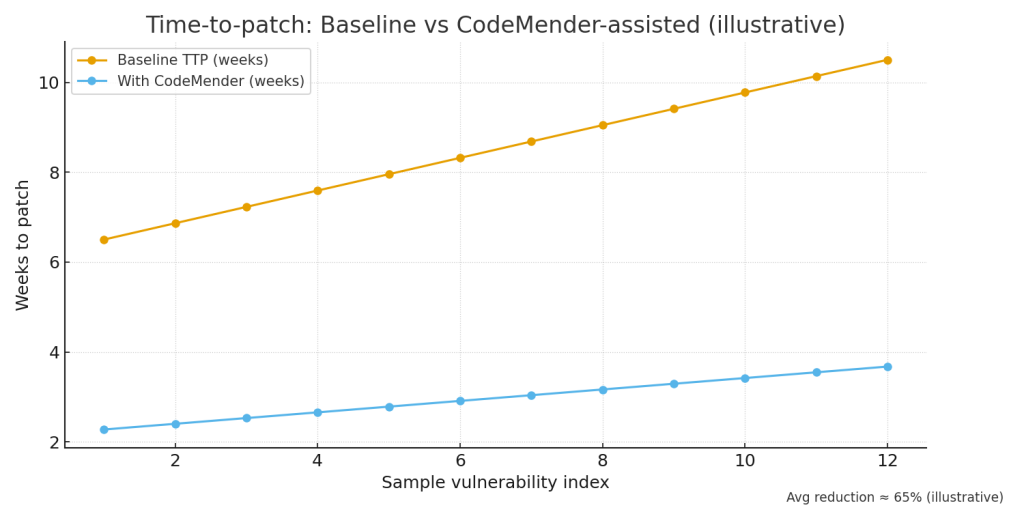
Time-to-patch comparison (illustrative): for a sample of 12 vulnerabilities the average TTP can drop by roughly ~65% when candidate patches and validation are automated. See the line chart for a sample comparison.
Note: the charts are illustrative and intended to show the expected direction and relative scale of the benefits reported.
How CodeMender actually works — a bit more technical detail
Hybrid approach: The system uses classical program analysis (fuzzers, static analyzers) to produce high-fidelity bug reports and stack traces. The LLM focuses on synthesizing a patch given the localized context and suggested test cases.
Patch validation: Candidate patches run through CI, unit tests, and targeted fuzzing to detect regressions and ensure the fix addresses the root cause. Only passing patches are promoted as candidates for human review.
Upstream process: For open-source projects, CodeMender prepares PRs with a clear description of the issue, the patch rationale, and the test artifacts. Maintainers can accept, modify, or reject them.
This blend reduces hallucination risk (LLMs inventing plausible but wrong code) because the LLM’s output is immediately tested against the project’s own tests and fuzzers.
Limitations and risks (be realistic)
Regression risk: Even verified patches can change intended behavior. Business logic can be subtle; full test coverage is rare. Human review remains essential.
False sense of security: Overreliance on automated fixes could lead to underinvestment in security processes and ownership.
Licensing and governance: Automatically proposing patches raises questions: who is responsible if an automated patch causes a problem? What legal/CLA implications exist?
Attack surface: Tools that produce code automatically could be abused if their models are tricked; proper access control and audit trails are required.
Practical recommendations for maintainers and security teams
Run candidates in a sandboxed CI pipeline that includes unit tests, integration tests and targeted fuzzing before any merge.
Require a human sign-off for patches that touch security-critical code paths or business logic.
Log provenance: store metadata about what generated a patch, which tests were run and who approved it. This is vital for auditing.
Pilot on dependencies and low-risk modules: use automation first where false positives are low and impact is moderate (utility libraries, documentation, helper functions).
Integrate with SCA/CI tools: connect CodeMender-like outputs to existing scanning and dependency management workflows.
Analysis: likely short- and medium-term impacts
Short term (6–12 months)
Increased velocity of small, high-confidence fixes in OSS libraries. More PRs automated; maintainers get more help triaging.
Tooling vendors will integrate similar features (e.g., GitHub/GitLab plugins that accept automated candidate patches).
Organizations will experiment with internal pilots for non-critical services.
Medium term (1–3 years)
Automated remediation becomes a normal part of the security pipeline. Integration into CI/CD and SCA tools becomes standard.
New governance models and policies emerge to manage the legal and operational aspects of automated code changes.
Attackers also adopt AI-assisted techniques — an ongoing arms race.
Interesting facts and context
CodeMender is not intended to fully replace developers — DeepMind frames it as a tool to augment maintainers, not to auto-merge code without oversight.
The hybrid design (LLM + classical analysis) is now a common pattern across applied AI safety/security projects because it balances creativity and verifiability.
CodeMender’s early upstreamed fixes include real projects with substantial codebases, showing the approach can scale beyond toy examples.
Final takeaway
CodeMender is a promising step toward automated remediation. It demonstrates that combining LLMs with rigorous validation can reduce time-to-patch and scale security work in open-source ecosystems. Still, the method is only as good as its validation, governance and integration with human reviewers. When used responsibly — sandboxed, audited, and with human sign-offs for critical code — tools like CodeMender could materially improve software security at scale.