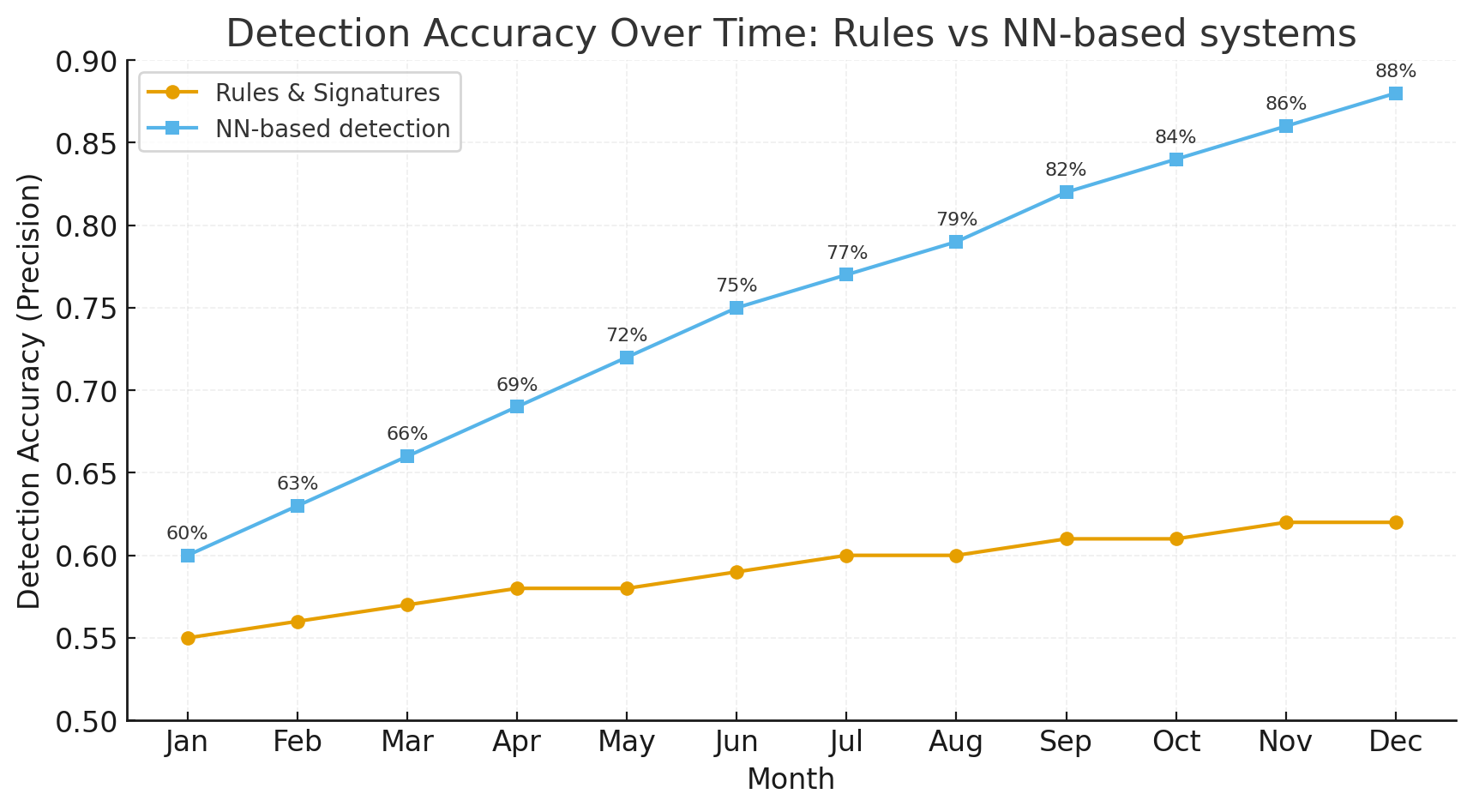
Web attacks remain the most common initial vector in modern incidents. Classic signature and rule-based defenses are necessary, but insufficient: they miss novel patterns, produce high noise, and struggle with complex, multi-step attacks. Neural networks — from autoencoders to graph neural networks and Transformers — bring a contextual, pattern-oriented layer that detects subtle anomalies across time, entities and relationships. When deployed thoughtfully (hybridized with rules, instrumented for explainability, and operated with retraining and feedback loops), NN-driven systems can significantly reduce mean time to detect (MTTD), lower analyst load, and cut false positives.
This article walks through architectures, modeling patterns, operational practices, and hands-on mitigation tactics for building effective real-time NN-based web detection systems.
Why neural networks — beyond the hype
Rule engines and WAF signatures catch well-known TTPs but fail in three common scenarios:
-
Novel or mutated attacks — zero-day techniques, typosquatting or obfuscated payloads.
-
Behavioral attacks — slow, low-and-slow credential stuffing or multi-step exploitation that only reveals itself across many requests.
-
High dimensionality — many weak signals (headers, timing, sequence of paths, user interactions) combine non-linearly into a malicious pattern.
Neural networks excel at modeling nonlinear relationships and temporal dependencies. Key practical benefits:
-
Sequence modeling (RNNs/Transformers) finds suspicious orderings of requests.
-
Anomaly detection (autoencoders, contrastive learning) surfaces outliers without labeled attacks.
-
Graph models expose coordinated campaigns (clusters of IPs, accounts, endpoints).
-
Representation learning compresses high-dimensional signals (text, headers, embeddings) into compact vectors usable by downstream systems.
Important caveat: NNs are tools, not silver bullets. They work best in hybrid architectures that blend deterministic rules for high-confidence blocks and ML for nuanced decisions.
Architectures and algorithms that matter
Below are the approaches you’ll see in effective production stacks — why they’re used and where they fit.
Autoencoders & Variational Autoencoders (VAE)
Use: unsupervised anomaly detection on session feature vectors.
How: train to reconstruct “normal” sessions; high reconstruction error => anomaly.
Pros: no labeled attacks required.
Cons: can flag benign but rare behavior; needs drift management.
Recurrent Networks (LSTM/GRU) and Temporal CNNs
Use: model sequences of URLs, parameters and inter-arrival times for session analysis.
How: predict next event or classify sequences.
Pros: naturally handle ordering and timing.
Cons: may struggle with very long contexts; careful engineering needed to avoid latency spikes.
Transformer-based models
Use: long-range dependencies and attention over many events (e.g., complex session histories).
How: use attention to focus on influential tokens/requests.
Pros: strong context modeling.
Cons: higher compute; use distillation/quantization for real-time.
Graph Neural Networks (GNN)
Use: model relationships between IPs, users, endpoints and attackers.
How: build entity graph (nodes: accounts, IPs, devices; edges: interactions) and detect anomalous subgraphs.
Pros: finds coordinated campaigns and lateral movement.
Cons: graph maintenance and near-real-time updates are operationally complex.
Contrastive & Self-Supervised Learning
Use: fine representations when labeled data is scarce.
How: train models to distinguish similar vs dissimilar examples, then use deviations as anomalies.
Pros: robust in nonstationary environments.
Cons: engineering complexity in crafting positive/negative pairs.
Hybrid stacks (rules + ML + orchestration)
Use: production systems.
How: rules handle known badness; cheap ML for triage; heavy NN + enrichment for high-risk events; orchestrator chooses action.
Pros: balances speed, cost and explainability.
Cons: requires orchestration and careful policy design.
Behavioral analytics — what to model
Behavior is your richest signal. Focus on modeling:
-
Session sequences. Order of endpoints, parameter patterns, request types and content.
-
Input patterns. Speed of typing, form-field order, copy/paste events (client instrumentation).
-
Rate and timing. Inter-arrival time distributions, burst patterns, time-of-day anomalies.
-
Cross-entity signals. Same IP hitting many accounts, accounts accessed from unusual geos, device fingerprint changes.
-
Graph activity. Clusters of accounts or IPs that interact similarly over short windows.
Rather than flagging single suspicious requests, score sequences and entity trajectories — the whole story often distinguishes benign from malicious.
Feature engineering best practices
NNs reduce but do not eliminate the need for thoughtful features:
-
Compact embeddings for text fields. Use pretrained sentence or param embeddings rather than raw text.
-
Hashed path and param tokens. Convert URLs and params to stable hashed tokens or categorical IDs.
-
Temporal features. Deltas between events, session duration, rolling counts.
-
Aggregations. Unique endpoints per session, entropy of headers, median inter-arrival time.
-
Reputation & enrichments. ASN, WHOIS age, TLS fingerprint, known badlists — these remain powerful.
-
Weak supervision labels. Seed rules and heuristics to create pseudo-labels for initial supervised training.
Feature stores and real-time aggregation layers are essential to compute these efficiently for inference.
Supervised vs unsupervised vs semi-supervised
-
Supervised: high accuracy when you have quality labeled attacks. Downside: labels are expensive and can be stale. Use it for high-value scenarios (payment fraud, known exploit signatures).
-
Unsupervised: good for unknown unknowns. Use autoencoders or density estimation to flag anomalies. Requires robust mechanisms to filter benign rarity.
-
Semi-supervised / weak supervision: combine signatures to pseudo-label and use NN to generalize. This is the pragmatic default for many SecOps teams.
Most production systems deploy hybrid approaches: unsupervised for discovery, supervised for high-certainty flows, and semi-supervised to scale.
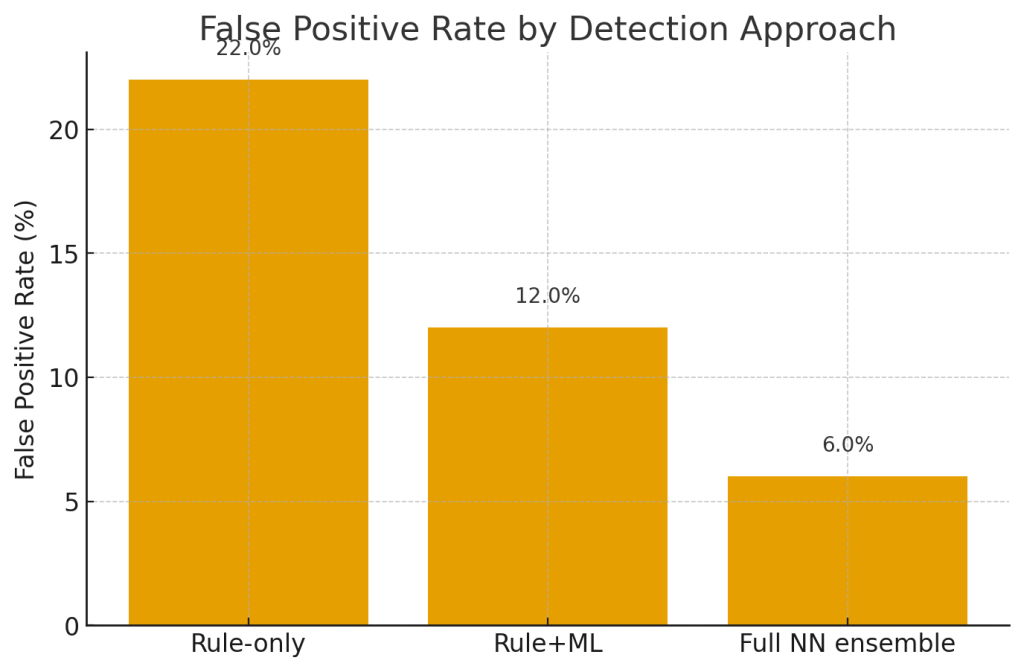
Reducing false positives — operational levers
False positives (FPs) are the single biggest operational cost. Here’s how to reduce them without losing detection power.
1. Multi-stage triage pipeline
-
Stage 0: deterministic rules (block/allow lists, rate limits).
-
Stage 1: lightweight ML triage (fast models giving initial score).
-
Stage 2: heavy analysis (deep NN, RAG with logs and context).
-
Stage 3: human review only for gray cases.
This design keeps latency low and reduces analyst load.
2. Model calibration and thresholding
Use calibration methods (Platt scaling, isotonic regression) so scores reflect true probabilities. Tune thresholds based on business impact: what is cost of one FP vs one FN?
3. Explainability & human workflows
Return reasons (top contributing features, attention highlights, reconstruction errors) to help analysts triage quickly. Explainability improves trust and speeds feedback.
4. Feedback loop and continuous retraining
Log analyst decisions (approve/reject) and feed them back. Daily/weekly retraining with balanced datasets reduces recurrence of the same FPs.
5. Ensembling & rule fusion
Combine multiple weak learners (sequence model, graph score, text classifier) and rules. Ensembles typically reduce variance and FPs.
6. Contextual thresholds
Apply different thresholds per segment: VIPs, internal accounts, partner IP ranges. Adaptive thresholds reduce impact on critical users.
7. Shadow mode & canaries
Run models in shadow for weeks to observe FPR in production before enforcement. Canary rollouts with small traffic slices let you validate behavior.
Handling model drift & adversarial behavior
Models drift — both benign user behavior and attacker techniques change. Mitigate drift by:
-
Continuous distribution monitoring. Monitor KS tests or feature distribution shifts.
-
Data/versioning. Keep snapshots of features, configurations and models.
-
Scheduled retraining. Automate retrain cadence with validation.
-
Adversarial testing. Periodic red-team simulations to probe for bypasses and weaknesses.
-
Graceful rollback. Canary and quick rollback reduce impact of bad updates.
Remember — attackers will try to game your model. Build processes to detect and respond.
Real-time system constraints: latency, throughput, scaling
Design must balance latency and fidelity:
-
Latency budgets. Inline blocking often needs <10–50 ms; triage can tolerate 100s of ms to seconds.
-
Throughput. Your stack must handle peak bursts; batch inference and autoscaling are crucial.
-
Model optimization. Use distillation, pruning, quantization, and optimized runtimes (ONNX/TF-TRT) for inference speed.
-
Edge vs cloud split. Deploy tiny models at edge/CDN for initial filtering; deep models run centrally for enrichment.
-
Fallbacks & circuit breakers. If model infra fails, fall back to rules or safe defaults to avoid service disruption.
End-to-end architecture pattern
A resilient real-time detection stack typically includes:
-
Ingest & prefilter (edge / CDN). Collect headers, IP, geo, minimal body; enforce rate limits.
-
Feature computation & store. Real-time aggregations for session context; maintain rolling windows.
-
Lightweight triage service. Fast model scoring for immediate decisions.
-
Enrichment & deep analysis. Heavy NN models, RAG with historical logs and threat intel.
-
Decision engine. Combine rules + model ensemble → action (allow, challenge, hold, block).
-
Human analyst UI. Present context, model reasons and action buttons with one-click remediation.
-
Feedback pipeline. Analysts’ choices and outcome data fed to training pipelines.
-
Monitoring & observability. Metrics for latency, MTTD, FPR, cost and model drift.
This pipeline balances speed, accuracy and operational transparency.
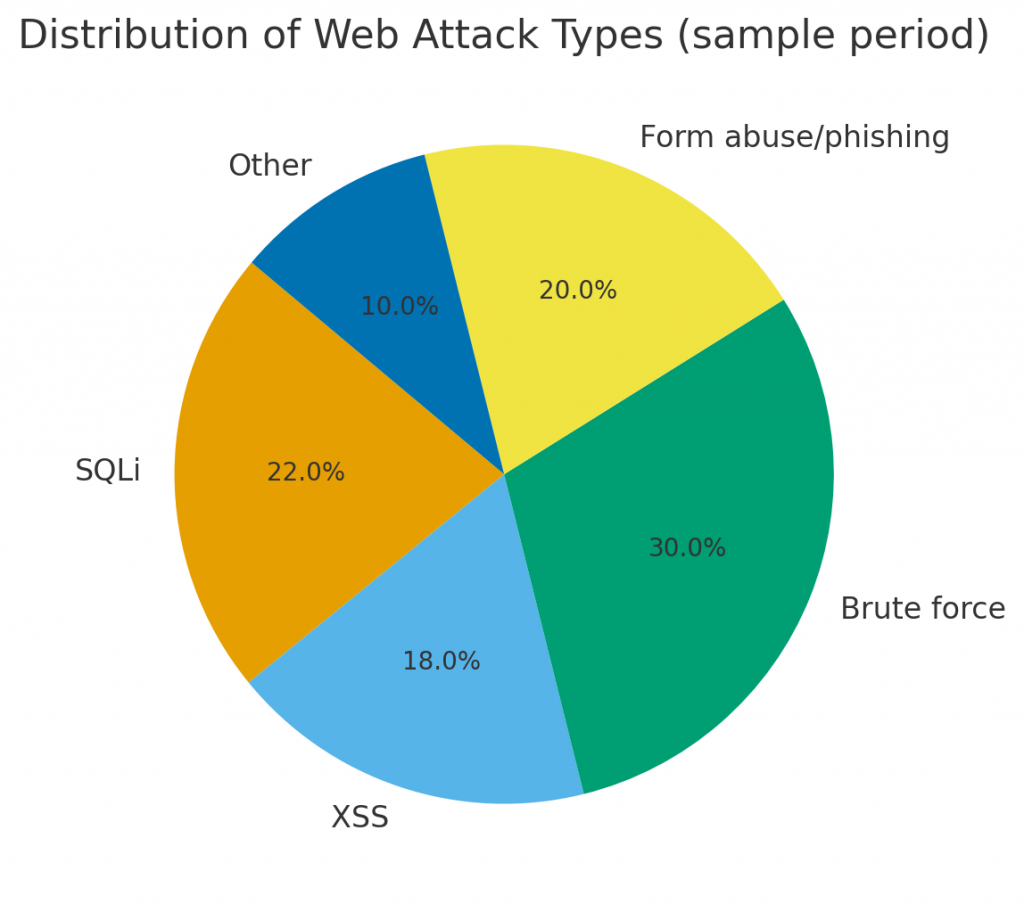
Practical use cases & expected outcomes
-
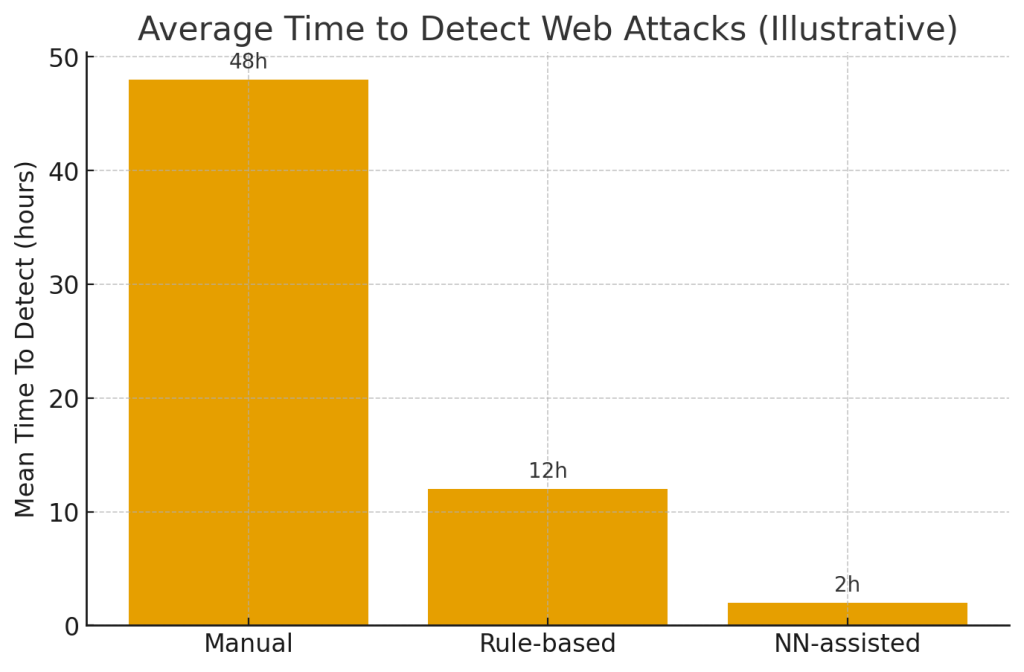
Brute-force / credential stuffing detection. Sequence models detect bursts and abnormal login patterns; expected MTTD improvements often exceed 70% versus manual review.
-
Contact-form abuse and phishing detection. Embedding-based classifiers flag manipulative language and suspicious links, reducing successful phishing submissions.
-
Coordinated botnets & scraping. GNNs reveal clustered activity across multiple accounts or endpoints and enable targeted mitigation.
-
Zero-day exploit signals. Autoencoders identify anomalous payload fingerprints even before signatures exist.
Illustrative (not universal) results organizations report: detection accuracy uplift of 10–30 p.p., FPR reduction from ~20% (rule-only) to under 5% with NN ensembles, and MTTD drop from days to hours (or hours to minutes) depending on workflow.
Interesting industry facts & context
-
A large portion of data breaches start with web-layer exploitation or credential compromise. While exact percentages vary by study, many reports place this number between 40–70% of incidents. The web layer is the broad attack surface of choice.
-
Analyst burnout is real — reducing FP by 20–30% directly correlates with meaningful SOC efficiency gains. Even small percentage improvements in FPR produce outsized operational benefits.
-
Hybrid approaches (rules + ML) consistently outperform either approach alone in production. NN-only systems often struggle with explainability; rules provide deterministic anchors for blocking.
Metrics SecOps/CTO/SRE should track
-
Precision / Recall (or precision@k) for flagged events.
-
False Positive Rate (FPR) and False Negative Rate (FNR) across segments.
-
Mean Time To Detect (MTTD) and Mean Time To Remediate (MTTR).
-
Containment rate — percent of attacks contained automatically.
-
Operational cost — inference compute, engineering hours, and analyst time per alert.
-
Model drift indicators — feature distribution shifts and validation performance over time.
-
User impact metrics — percent of legitimate transactions impacted or degraded.
Measure costs of FP in dollar hours and lost revenue to inform threshold decisions.
Roadmap: how to pilot and scale
Phase 0 — readiness: inventory logs, data quality, latency constraints and labeling capacity.
Phase 1 — POC (2–6 weeks):
-
Build a shadow pipeline using autoencoder or small sequence model.
-
Run on historical data and then live shadow traffic.
-
Measure FPR, precision and MTTD.
Phase 2 — iterate (6–12 weeks):
-
Add graph features, supervised components for known attack classes.
-
Implement multi-stage triage and human UI.
-
Tune thresholds, calibrate scores.
Phase 3 — production hardening (3–6 months):
-
Optimize models for inference, add canary rollouts, enforce retrain cadence.
-
Implement observability and governance (who approves model changes).
-
Run regular red-team and adversarial tests.
Phase 4 — scale & continuous improvement:
-
Expand to new flows, integrate with SIEM/SOAR, automate remediation playbooks.
Pitfalls & how to avoid them
-
Chasing “detect everything”. Focus on high-impact scenarios first.
-
Underinvesting in data ops. Labeling, retention, feature stores and privacy redaction take significant effort.
-
No explainability. Analysts won’t trust black boxes; provide reasons.
-
No retrain plan. Models degrade without scheduled updates.
-
No canary or shadow testing. Never flip enforcement without baseline testing.
Conclusion
Neural networks materially enhance real-time web-attack detection by modeling complex behavior, temporal patterns, and entity relationships that rules alone cannot capture. The practical path to value is iterative: start small, run in shadow, combine deterministic rules with lightweight ML, then selectively apply heavy NN models and graph analysis for high-risk flows. With robust explainability, calibration, and feedback loops, NN-enabled systems lower false positives, reduce detection times, and make SecOps teams far more effective — while maintaining the deterministic safety net of traditional defenses.